Objekt Orienterad Programmering med C# Del 2: Arbeta med klasser

Innehållsförteckning
Introduktion
I den 2:a delen av objekt orienterad programmering med C# ska vi titta lite närmare på hur vi arbetar med klasser och skapar objekt utifrån dem. Vi kommer även att kika på hur vi ser till att tillståndet är korrekt initierat vid skapandet av ett objekt.
Dessutom kommer vi att diskutera metoder, hur vi skyddar våra klass och objekt medlemmar ifrån otillåten åtkomst. Vi kommer att diskutera fält och åtkomst till värden på våra fält. Vi kommer även att kika på hur vi kan hantera våra fält som egenskaper och slutligen ska vi se hur vi kan simulera en klass och dess objekt att fungera som en lista eller array.
I den här delen ska jag också visa på ett exempel som kommer ifrån ett av mina kund projekt. Givetvis kommer det att vara en förenklad version av koden som jag använde vid det tillfället.
Start av projektet
Vad vi ska producera är en klass som innehåller den grundläggande information som representerar vår beställares faktura.

Skapa applikationen
Så låt oss nu öppna vårt terminal- eller konsol-fönster.
Jag kommer att hänvisa till terminal fönstret hädanefter mest beroende på att jag utvecklar på min Mac. Sitter ni på Windows och vill använda det inbyggda kommando verktyget(command tools) så öppnar ni det istället. Använder ni Windows och har installerat git så har ni även tillgång till ett bash fönster som fungerar som terminal fönstret i Mac.
I terminal fönstret navigera till en plats där ni vill placera applikationen och skriv in följande kommando för att skapa en ny konsol applikation som får namnet InvoiceApp och hamnar i en katalog som får namnet InvoiceApp.
Kom ihåg ifrån introduktionsdelen att flaggan -n låter oss skapa ett namn och katalog för applikationen. Vi kommer att se på fler val som vi kan använda lite längre fram.
dotnet new console -n InvoiceAppNär applikationen är skapad så navigera in i katalogen där den blev skapad och skriv kommandot code . i terminalfönstret.
När VS Code öppnas upp så glöm inte att svara Yes på frågan om att lägga till inställningar för att kunna köra och avlusa applikationen.

När detta är gjort så får vi en ny mapp i Explorer fönstret(.vscode). Öppna nu upp Program.cs filen i editor fönstret.
Vi behöver göra en förändring i vår Program.cs fil. Ändringen som vi behöver göra är att återgå till en standard hantering av uppstart av en .NET console applikation.
Från och med version 6.0 av .NET har Microsoft minimerat koden inuti Program.cs filen för att bara innehålla minimalt med det som behövs för att köra console applikationer.
På rad två bör ni se en liten gul glödlampa, om den inte syns placera musmarkören på rad två. Då bör den dyka upp, klicka på den och välj alternativet "Convert to 'Program.Main' style program".
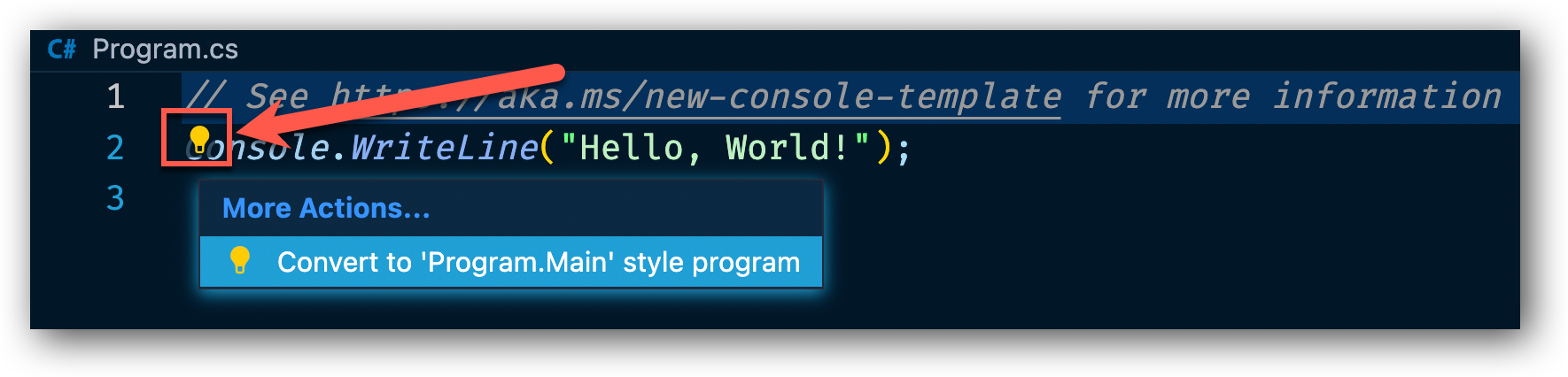
Nu bör Program.cs filen se ut som nedan.
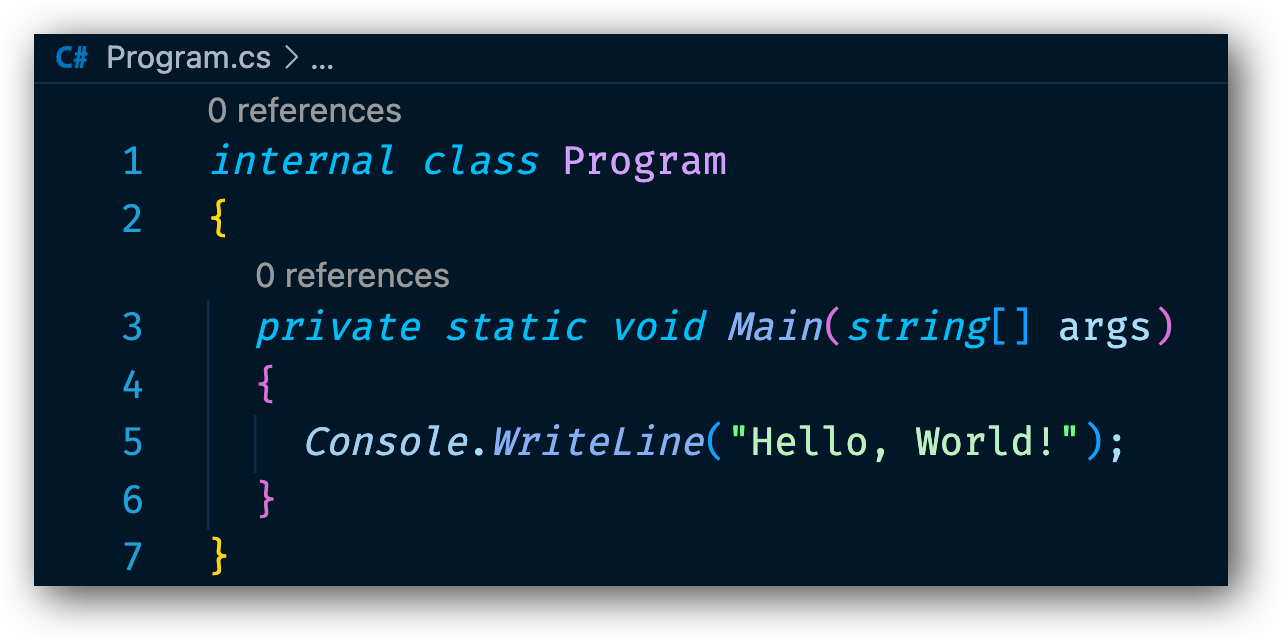
Vi kan städa upp Main metoden lite, ta bort argumentet string[] args ifrån metoden. Vi behöver inte argumenten för vår applikation. Vi kan även ändra strängen som skrivs ut till "Vår Invoice App fungerar!".
När detta är gjort så öppnar vi upp den inbyggda terminalen i VS Code. Ni hittar den via Terminal menyn i VS Code, välj "New Terminal". I terminal fönstret skriv in kommandot dotnet run.
Vi bör då se resultatet
Vår Invoice App fungerar!Nu har vi grunden klar, så nu kan vi börja att fokusera på att skapa och konstruera vår Invoice klass.
Ett alternativt sätt är att använda en extra flagga för att skapa en konsol applikation med .NET 6 eller .NET 7.
dotnet new console -n InvoiceApp --use-program-main trueDetta skapar en applikation med en Program klass och en Main metod utan att behöva utföra ovanstående manöver
Invoice class
Med hjälp av UML diagrammet ovan så skapar vi följande klass. Placera musmarkören efter klassen Program och skriv in följande kod:
internal class Program
{
private static void Main()
{
Console.WriteLine("Vår Invoice App fungerar!");
}
}
// Vår Invoice klass...
public class Invoice
{
// Våra fält...
public string InvoiceNumber;
public DateTime InvoiceDate;
public string PaymentTerms;
public string PurchaseOrder;
public string OrderNumber;
public string CustomerNumber;
public string Currency;
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}Ni kommer förmodligen se ett antal fält som har fått gul markering, detta är ingenting att oroa sig för tillfället. Det är bara en varning om att vi inte har gjort allting enligt de nya reglerna i .NET 6.0. Vi kommer om en stund att hantera denna varning.
Däremot så ser vi nu att i en och samma fil har vi två klasser. Klassen Program och klassen Invoice. Detta är inte att rekommendera, men jag gjorde detta av en enkel anledning och det var att få visa Er VS Code's möjlighet till refactoring.
Om vi nu tar och ställer musmarkören framför public class Invoice och trycker på Cmd+. på Mac eller Ctrl+. på Windows. Så får vi fram en meny där vi kan välja olika uppgifter som vi vill utföra på klassen. Det enda vi vill göra just nu är att skapa en ny fil för vår klass, därför väljer vi alternativet "Move type to Invoice.cs".
Observera att när det står antingen Cmd+. eller Ctrl+. så betyder det att hålla ner Cmd eller Ctrl tangenten och sedan tryck på punkt tangent.
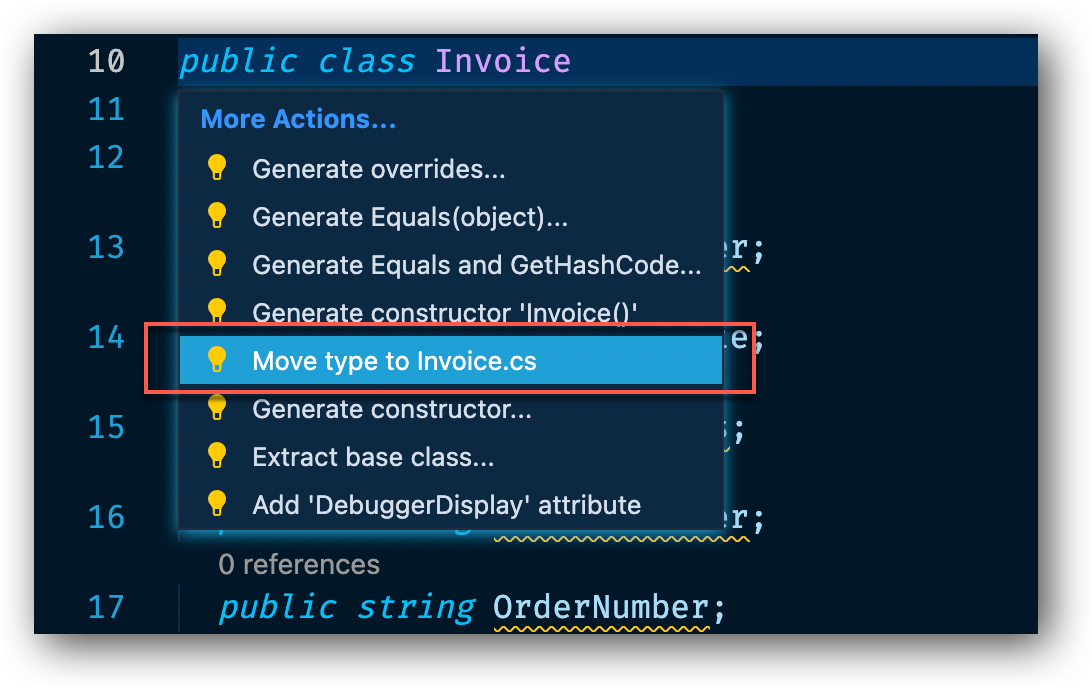
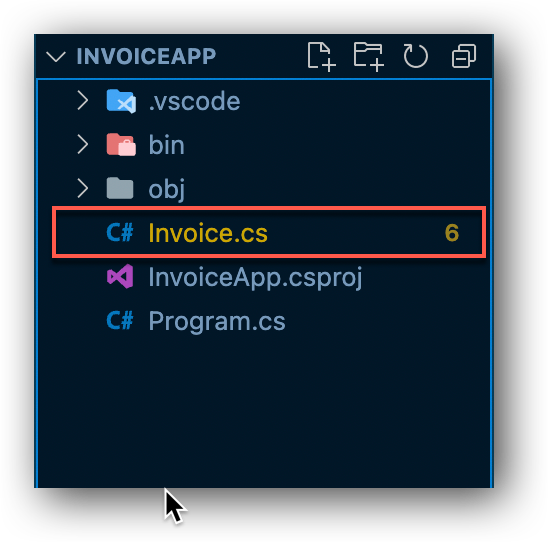
När vi väljer detta alternativ ser vi att klassen försvinner ifrån Program.cs filen. Tar vi nu och tittar i Explorer fönstret så ser vi vår nya fil och klickar vi på filen så ser vi att vår Invoice klass nu är flyttad till en egen fil.
Låt oss använda Invoice klassen
Så låt oss nu se hur vi kan använda vår nya Invoice klass. Så låt oss gå tillbaka till vår Program klass i Program.cs och lägg till följande kod i Main metoden.
internal class Program
{
private static void Main()
{
// Lägg till denna rad för att instansiera ett nytt objekt ifrån
// klassen Invoice...
Invoice newInvoice = new Invoice();
Console.WriteLine("Vår Invoice App fungerar!");
// Lägg till denna rad bara för att få ut något i konsol fönstret...
Console.WriteLine(newInvoice);
}
}
Låt oss nu köra vår applikation och se vad som händer. I VS Code's terminal skriv in kommandot dotnet run och se vad som händer. Oooops så mycket gul text det dök upp. Gul text betyder varning och det i sin tur betyder att vi potentiellt kan ha gömda buggar i vår applikation. Den fungerar i och för sig, för det kan vi se längst ner där vi får vårt resultat. Men det kan vara så att applikationen visar sig fungera nu men plötsligt börjar bete sig konstigt efter ett tag.
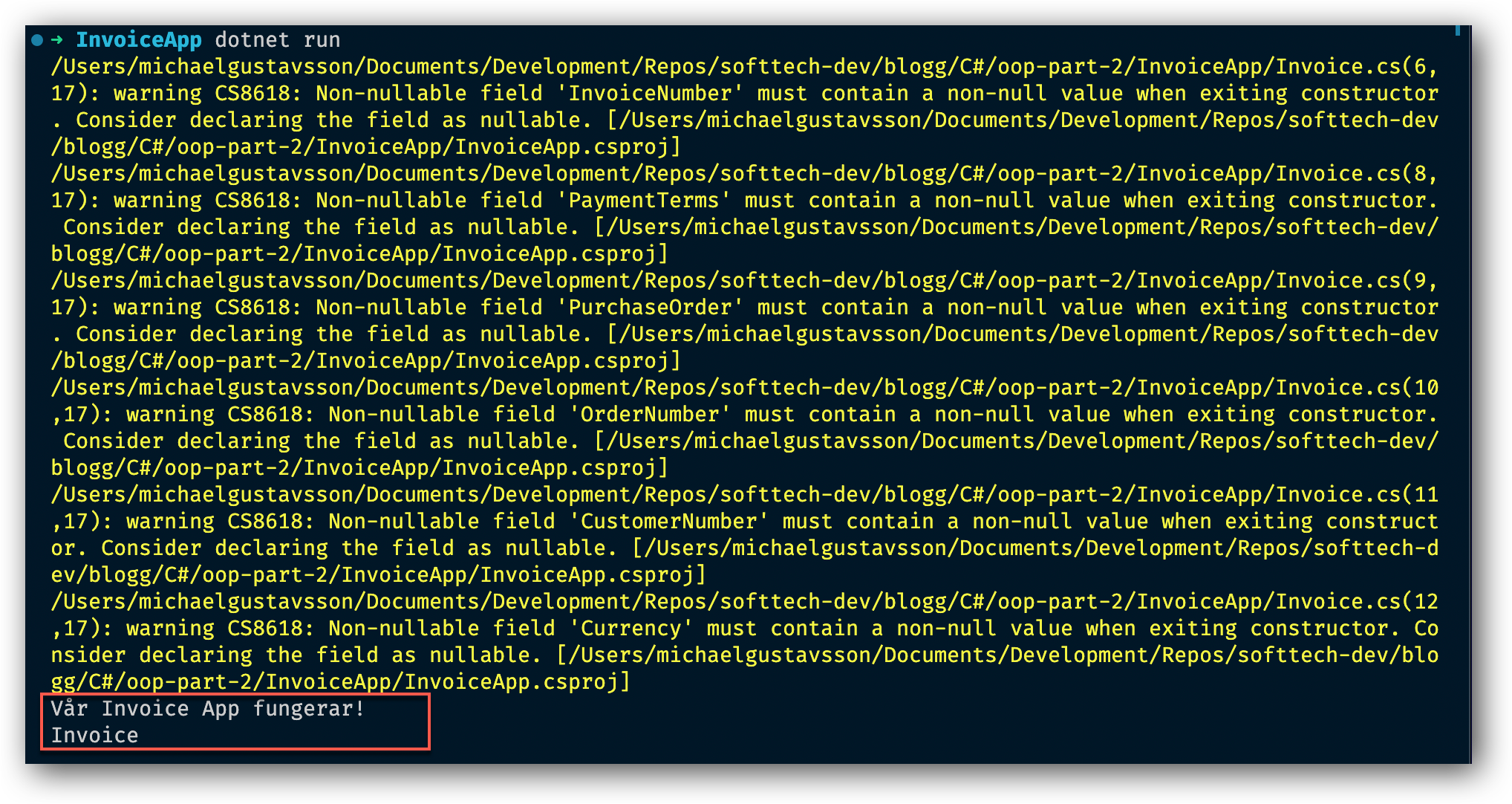
Så vad betyder varningarna då?
Låt oss se vad som står i varningarna. Identifiera en varning, t ex den första som säger warning CS8618.
warning CS8618: Non-nullable field 'InvoiceNumber'
must contain a non-null value when exiting constructor.
Consider declaring the field as nullable.
Läser vi igenom alla varningar ser vi att det är samma varning men för olika fält i vår klass Invoice.
Vad betyder då detta? Den säger att fältet 'InvoiceNumber' som inte tillåter null måste sättas till ett värde annat än null när den lämnar klassens konstruktor eller att tillåta den vara null.
Detta betyder att fältet InvoiceNumber som vi har deklarerat som ett fält i vår klass inte får vara null(non-nullable) när klassen skall instansieras till ett objekt. OK vad är då null? Null är ett begrepp som funnits inom utveckling och databashantering i många, många år. Null betyder okänt värde, inte 0 eller tom sträng. Utan helt enkelt vi vet inte vad dess värde är. För att lösa detta måste vi se till att alla datatyper som inte tillåter null har ett värde innan objektet skapas.
Hur löser vi detta då?
Men innan vi löser detta måste en sak förklaras. Exakt samma kod hade fungerat utan varningar i tidigare versioner av .NET 6.0. Detta är något som Microsoft införde eller implementerade i .NET 6.0. Anledningen var och är att skydda oss ifrån att försöka använda något som inte är initierat eller instansierat.
Vi kan se detta om vi öppnar upp projekt filen som i vårt fall heter InvoiceApp.csproj.
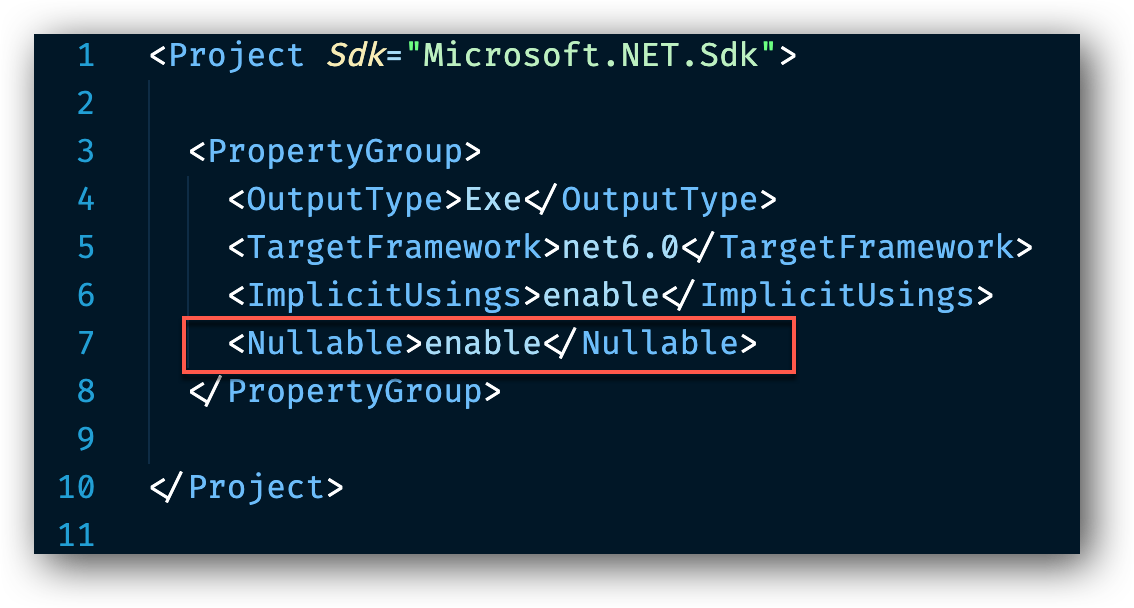
Om vi tittar på rad 7 så finns där ett element <Nullable>enable</Nullable> som aktiverar denna kontroll. Detta är nytt för .NET 6.0 och uppåt.
Det går att ändra denna inställning och sätta den till disable. Detta är inte rekommenderat utan bara i de fall där vi håller på att uppgradera en applikation ifrån en tidigare version av .NET till version 6.0
Om vi läser varningen igen så säger varningen något om constructur. Detta betyder att vi skulle kunna använda en constructor för att sätta värden på våra fält som inte får vara null. Vi har inte pratat eller gått igenom constructors ännu utan vi kommer att göra det i nästa sektion i denna modul.
Lösning
Det finns två lösningar på detta problemet:
- Tillåta fältet att vara null
- Sätta ett startvärde eller standardvärde på respektive fält.
Så låt oss börja att titta på alternativet att tillåta fältet att vara null. Om vi går tillbaka till vår Invoice klass och letar upp alla fält som har en gul varning och gör följande justering.
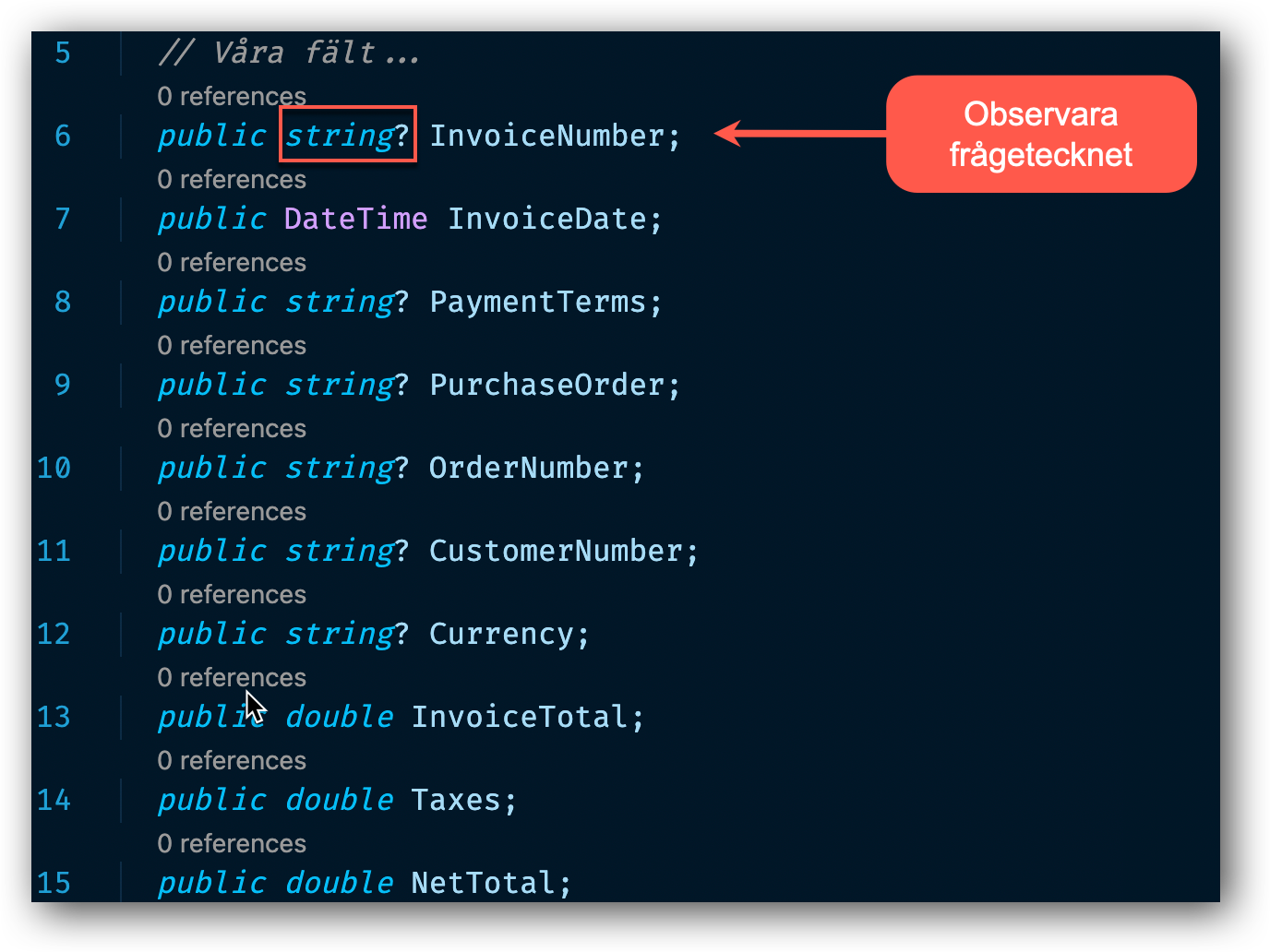
För varje non-nullable fält har vi nu placerat ett ?(frågetecken) efter typen(string). Detta gör nu att vi säger till C# kompilatorn att alla fält med ? nu kan innehålla null(ett okänt värde). Testkör vi igen vår applikation kommer vi se att allt fungerar och inga varningar dyker upp.
Är detta en bra lösning. Ja ibland är det en bra lösning. Framförallt om vi inte vet vid skapandet av klassen vad för värden som ska placeras i fälten. MEN med stora bokstäver, vi lägger nu ansvaret på de utvecklare som ska använda vår klass att kontrollera att fälten inte innehåller null. I så fall i värsta fall så kraschar applikationen. Så min slutsats och rekommendation är att undvika så mycket det går att tvinga ett fält att få vara null vid design av klasser. Bara i nödfall använda det.
Istället ska vi se på alternativet att ge varje fält ett standardvärde eller startvärde. Så tillbaka till vår Invoice klass, se till att ta bort alla frågetecken och istället ge varje fält ett standardvärde. I vårt fall i och med att det handlar om fält med typen string, så sätter vi ett värdena till tom sträng.
// Våra fält...
public string InvoiceNumber = "";
public DateTime InvoiceDate;
public string PaymentTerms = "";
public string PurchaseOrder = "";
public string OrderNumber = "";
public string CustomerNumber = "";
public string Currency = "";
public double InvoiceTotal;
public double Taxes;
public double NetTotal;Om vi nu kör om applikationen så ska vi se att allting fungerar utan varningar.
Frågan är nu bara är det ett korrekt sätt att lösa problemet på eller finns det andra sätt. Vi får se😁.
Detta var en ganska lång inledning på denna modul. Det var även lite repetion ifrån förra men nu har vi allt vi behöver för att ta nästa steg och det är att designa om klassen på ett mer objekt orienterat sätt.
I nästa sektion ska vi se på det som varningarna föreslog vilket var att använda en konstruktor eller constructor som är det korrekta begreppet.
Jag kommer hädanefter referera till namnet constructor för det är så utvecklare är vana att se begreppet.
Constructors
I den här sektionen ska vi ta upp allt om constructors och hur och när vi använder dem men först
Vad är en constructor?
En "constructor" är en metod som anropas automatiskt när ett objekt ska skapas ifrån en klass. Det måste alltid finnas en constructor, även i vårt enkla exempel hittills. Vänta nu lite säger ni, vi har ju inte skapat en constructor metod. Vad menar du med att det måste finnas en constructor metod?
Ja det måste alltid finnas en constructor metod för att sätta igång processen med att skapa ett objekt. Hur kan det då komma sig att vår applikation fungerade, vi skapade aldrig en constructor metod?
Anledningen är att C# kompilatorn är intelligent, om den inte hittar en constructor metod så skapar den en standard constructor metod som inte tar några parametrar eller argument och kan på så sätt fortsätta med att skapa objektet vi behöver ifrån vår klass. Den constructor metod som C# kompilatorn sätter standardvärden på våra fält. Vad för värden får vi då?
- Heltals fält får värdet 0
- Flyttals fält får värdet 0.0 (ibland 0.00)
- Booleska fält får värdet false
- Referenstyper som t ex strängar får inget värde från och med version 6.0 av .NET. Därav varningarna vi diskuterade tidigare.
Varför behöver vi en constructor?
Den primära anledningen är att försätta objektet i ett korrekt tillstånd vid instansiering. Vad menas med detta då? Om vi minns så lagrar vi data fälten i ett objekt. Detta är vad vi kallar för objektets tillstånd eller data. Vad vi vill är att dessa fält har korrekt information när objektet skapas.
Hur skapar vi constructor metoder?
En constructor är helt enkelt en metod men med samma namn som klassen och som inte har någon retur typ. Så låt oss kika på hur vi kan skapa en constructor för vår Invoice klass.
public class Invoice
{
// Våra fält...
// Constructor metod, observera att metoden har samma namn som
// klassen och saknar retur typ.
public Invoice()
{
}
// Våra metoder (operations)...
}
Vi har nu skapat en constructor metod utan argument, vilket är precis vad C# kompilatorn gör åt oss om vi inte har skapat en constructor.
Observera att jag har placerat constructor metoden mellan våra fält och våra metoder. Vilket är god praxis.
Vi kan nu använda vår constructor metod för att initiera våra fält till de startvärden som vi finner vettiga.
Låt oss se på ett mycket enkelt exempel:
// Vår Invoice klass...
public class Invoice
{
// Våra fält
public string InvoiceNumber;
public DateTime InvoiceDate;
public string PaymentTerms = "";
public string PurchaseOrder = "";
public string OrderNumber = "";
public string CustomerNumber = "";
public string Currency = "";
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Vår constructor metod tar nu två argument...
public Invoice(string invoiceNumber, DateTime invoiceDate)
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}Om vi nu skapa en instans av vår klass Invoice måste vi använda vår nya constructor metod och skicka med de två förväntade argumenten. Vi kan inte nu längre strunta i argumenten vi får inte en standard constructor så fort vi har skapat en egen.
Låt oss se hur vi kan skapa en instans av vår Invoice klass med den nya constructor metoden.
internal class Program
{
private static void Main()
{
Invoice newInvoice = new Invoice("FY56789X", DateTime.Today);
Console.WriteLine("Vår Invoice App fungerar!");
Console.WriteLine("Fakturanummer: {0} Fakturadatum: {1}",
newInvoice.InvoiceNumber, newInvoice.InvoiceDate);
}
}
Om vi nu kör applikationen bör vi få följande resultat
Vår Invoice App fungerar!
Fakturanummer: FY56789X Fakturadatum: 2022-10-11 00:00:00
Om vi vill ha en standard constructor så får vi skapa en ny constructor metod. Så låt oss göra det.
// Vår Invoice klass...
public class Invoice
{
// Våra fält
public string InvoiceNumber;
public DateTime InvoiceDate;
public string PaymentTerms = "";
public string PurchaseOrder = "";
public string OrderNumber = "";
public string CustomerNumber = "";
public string Currency = "";
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Här är vår standard constructor...
public Invoice(){}
// Vår constructor metod tar nu två argument...
public Invoice(string invoiceNumber, DateTime invoiceDate)
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}
Vad vi har gjort nu är att skapa en överlagrad constructor metod
Om vi nu ändrar tillbaka till vår ursprungliga instansiering och kör igen.
internal class Program
{
private static void Main()
{
Invoice newInvoice = new Invoice();
Console.WriteLine("Vår Invoice App fungerar!");
Console.WriteLine("Fakturanummer: {0} Fakturadatum: {1}",
newInvoice.InvoiceNumber, newInvoice.InvoiceDate);
}
}
Så får vi plötsligt en varning, igen!
warning CS8618: Non-nullable field 'InvoiceNumber' must contain a non-null value when exiting constructor. Consider declaring the field as nullable.
Vad beror nu detta på?
Anledning är igen att vi inte har något värde på vårt fält InvoiceNumber. Vilket vi även kunde se på varningen i vår standard constructor när vi lade till den.
Hur löser vi detta problem?
Vad vi kan göra nu är att i vår standard constructor sätta ett standard värde på InvoiceNumber.
// Vår Invoice klass...
public class Invoice
{
// Våra fält
public string InvoiceNumber;
public DateTime InvoiceDate;
public string PaymentTerms = "";
public string PurchaseOrder = "";
public string OrderNumber = "";
public string CustomerNumber = "";
public string Currency = "";
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Här är vår standard constructor...
public Invoice()
{
InvoiceNumber = "Saknas";
}
// Vår constructor metod tar nu två argument...
public Invoice(string invoiceNumber, DateTime invoiceDate)
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}
Kör vi nu om vår applikation kommer vi att se att varningen är borta och applikationen fungerar korrekt igen.
Så nu när vi har en standard constructor kan vi ta bort standardvärdena på våra fält och använda vår constructor metod för att initiera värden vid instansiering av objektet. Så bara för sakens skull låt oss se hur det kan se ut i vår standard constructor.
// Vår Invoice klass...
public class Invoice
{
// Våra fält
public string InvoiceNumber;
public DateTime InvoiceDate;
public string PaymentTerms;
public string PurchaseOrder;
public string OrderNumber;
public string CustomerNumber;
public string Currency;
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Här är vår standard constructor...
public Invoice()
{
InvoiceNumber = "Saknas";
InvoiceDate = DateTime.Now;
PaymentTerms = "";
PurchaseOrder = "";
OrderNumber = "";
CustomerNumber = "";
Currency = "SEK";
InvoiceTotal = 0;
Taxes = 0;
NetTotal = 0;
}
// Vår constructor metod tar nu två argument...
public Invoice(string invoiceNumber, DateTime invoiceDate)
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}
Innan vi tar och diskuterar om ovanstående är bra och snyggt eller dåligt och "fulkod" ska vi kika på ytterligare exempel på överlagrade constructor metoder.
Dessvärre så efter vår ändring ovan så får vi nya varningar igen.
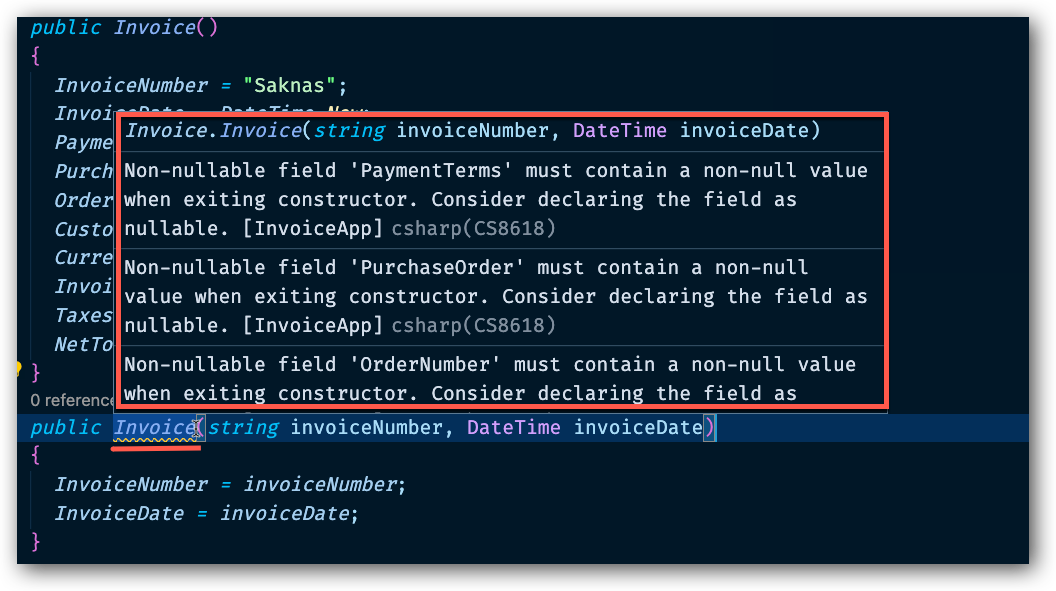
Så nu är vi tillbaka till samma problem igen. Vår constructor metod som tar argument initierar inte de övriga fälten korrekt.
Så vad är lösningen på detta problemet?
I detta specika fall så finns det två lösningar på problemet
- Initiera alla fält i vår constructor metod som tar två argument
- Låt vår constructor metod anropa standard constructor metoden
Om vi går på alternativ 1 så får vi duplicerad kod, vilket vi vill försöka undvika. Så detta är inget bra alternativ, men tyvärr är det kod som ni kommer att se i vissa applikationer.
Alternativ 2 låter mer vettigt, men hur får vi constructor metoden med argument att anropa constructor metoden utan argument(standard constructorn)?
Vi använder nyckelordet this. Så vad vi kan göra är följande:
public Invoice(string invoiceNumber, DateTime invoiceDate): this()
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
Observera syntaxen, efter constructor metoden så sätter vi colon(:) och direkt därefter nyckelordet this med tomma parenteser. De tomma parenteserna anger att vi vill anropa en constructor utan argument.
Nyckelordet this representerar det aktuella objektet, så när vi säger : this() så betyder det att anropa en constructor metod utan argument i den aktuella instansen av objektet vi försöker skapa.
Frågan är nu bara i vilken ordning körs våra constructor metoder. När vi instansierar ett objekt utifrån en klass genom att anropa vår constructor med argument. Så kommer inte koden i constructor metoden att köras förrän constructor metoden som :this() pekar på. I vårt fall betyder det att innan vår kod som sätter InvoiceNumber och InvoiceDate till de inskickade värdena så anropas vår standard constructor metod och koden i den constructor metoden körs. När den koden har kört färdigt så återlämnas kontrollen till vår ursprungliga constructor metod och vi sätter nu InvoiceNumber respektive InvoiceDate fälten till de värden som är inskickade som argument.
Ytterligare exempel på överlagrade constructor metoder
Vi ska nu se på ytterligare ett exempel som kanske förtydligar resonemanget.
Låt oss säga att vi behöver en constructor metod till som enbart tar in ett fakturanummer för att kunna hämta en specifik faktura och fylla objekts fält med information som vi hämtat.
Så låt oss se på ytterligare en constructor metod:
public Invoice(string invoiceNumber)
{
InvoiceNumber = invoiceNumber;
}
Nu får vi samma problem som tidigare. Vi får varningar om att vi inte har initierat non-nullable fields korrekt. Lösningen på detta är enkel, vi såg i tidigare exempel med vår constructor metod som tog två parametrar hur vi löste detta. Så låt oss fixa till vår constructor metod.
public Invoice(string invoiceNumber): this()
{
InvoiceNumber = invoiceNumber;
}
Allt verkar ok, inga fler varningar och applikationen bör fungera som tidigare. Men vi har nu duplicerad kod för att sätta värden på fälten.
public Invoice(string invoiceNumber): this()
{
InvoiceNumber = invoiceNumber;
}
public Invoice(string invoiceNumber, DateTime invoiceDate) : this()
{
InvoiceNumber = invoiceNumber;
InvoiceDate = invoiceDate;
}
Dupliceringen sker i vår constructor metod som tar parametrarna invoiceNumber och invoiceDate. Om vi tittar i koden för constructor metoden så ser vi att vi sätter InvoiceNumber till värdet av invoiceNumber. Vi har redan en constructor metod för att initiera fältet InvoiceNumber.
Detta är vad som i utvecklarkretsar kallas för "Smelly code" eller på svenska "Ful kod".
Frågan är nu hur vi löser detta då?
Lösningen är väldigt enkel, vi har sett hur vi kan använda :this med tomma parenteser. Vi kan även använda argument mellan parenteserna för att definiera vilken constructor metod som vi vill anropa. Så om vi skriver om vår constructor metod med de två parametrarna på följande sätt:
public Invoice(string invoiceNumber, DateTime invoiceDate) :
this(invoiceNumber)
{
InvoiceDate = invoiceDate;
}
Observera att nu på första raden skickar vi med värdet på parametern invoiceNumber till en constructor metod som tar ett argument av typen sträng och att vi nu kan radera raden som initierade InvoiceNumber i constructor metodens kod.
Nu har vi skapat en snygg och lättläst kod utan duplicering vilket är en viktig del av objekt orienteringens principer.
Det blev väldigt mycket och väldigt djupt om constructor metoder men det är av avgörande vikt att vi förstår hur det fungerar för att sedan diskutera hur och när vi ska använda dem.
Behöver vi constructor metoder?
Efter den långa förklaringen och beskrivningen av vad constructor metoder är och hur och varför vi använder dem. Så kommer jag med denna fråga, behöver vi dem?
Varför jag har gått igenom constructor metoder så noggrant är på grund av att många system/applikationer där ute i det vilda fortfarande arbetar med constructor metoder på det sättet som jag beskrivit det. Men jag ska nu visa på hur vi kan städa upp vår Invoice klass och gå tillbaka till början och se när vi verkligen behöver constructor metoder.
Refactoring av Invoice klassen
Så låt oss nu gå tillbaka och städa upp i vår Invoice klass, när vi är klara ska den se ut som följer:
public class Invoice
{
// Våra fält
public string InvoiceNumber = "";
public DateTime InvoiceDate;
public string PaymentTerms = "";
public string PurchaseOrder = "";
public string OrderNumber = "";
public string CustomerNumber = "";
public string Currency = "";
public double InvoiceTotal;
public double Taxes;
public double NetTotal;
// Våra metoder (operations)
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}
Så nu är alla våra constructor metoder borta och vi har återgått till att sätta standardvärden direkt på fälten. Frågan som ofta ställs i detta läge är hur sätter jag värden på mina fält om jag inte har någon constructor metod.
Vi ska alldeles strax få se ett exempel på hur vi gör detta.
Men först måste vi även göra några justeringar i vår Program klass. Så öppna upp Program.cs filen och se till att den ser ut som följer:
internal class Program
{
private static void Main()
{
var invoice = new Invoice();
Console.WriteLine("Vår Invoice App fungerar!");
Console.WriteLine("Fakturanummer: {0} Fakturadatum: {1}",
invoice.InvoiceNumber, invoice.InvoiceDate);
}
}
Som vi kan se här nu så har vi återgått till att använda den constructor metod som C# kompilatorn ger oss och det räcker gott och väl för oss i detta exempel. Jag har även för enkelhetens skull namngivit min referens till invoice istället för newInvoice. I mitt tycke ett bättre namn nu när vi håller på med refactoring. Som ni också förmodligen ser så har jag tagit bort typen Invoice framför min variabel och istället använder nyckelordet var, som gör att jag slipper skriva typen när jag deklarerar en variabel. Istället sköter C# kompilatorn detta åt mig genom att titta på vad det är för typ jag instansierar.
Om vi nu kör applikationen kommer den fortfarande att fungera!
Hur kan vi nu sätta värden på våra fält?
Svaret är enkelt, vi använder referens variabeln vi skapad och använder dot notation.
var invoice = new Invoice();
invoice.InvoiceDate = DateTime.Today;
invoice.CustomerNumber = "123456";
invoice.InvoiceNumber = "VX4356";
osv...
Kör vi applikationen kan vi se att den fortfarande fungerar och levererar de nya värden som förväntat.
När behöver vi en constructor metod?
Låt oss bygga ut vår lilla applikation med en ny klass, låt oss kalla den för Customer för att representera en kund. Skapa klassen i en ny fil Customer.cs.
public class Customer
{
public string CustomerNumber = "";
public string CustomerName = "";
}Vi har ingen constructor metod i Customer klassen utan initierar fälten med standardvärden. I detta fall bara tomma strängar. Låt oss nu säga att en kund har inga, en eller flera fakturor. Så låt oss representera det med en generic List av typen Invoice.
public class Customer
{
public List<Invoice> Invoices;
public string CustomerNumber = "";
public string CustomerName = "";
}Här har vi skapat ett fält av typen generic List, som vi hittar i namespace System.Collections.Generic, som vi namnger Invoices. Ignorera varningen som vi har fått på fältet Invoices.
Denna varning ser vi enbart för att vi använder .NET version 6.0. Hade vi haft en tidigare version hade vi aldrig blivit varnad.
Så låt oss uppdatera vår Program klass i Program.cs fil.
internal class Program
{
private static void Main()
{
var customer = new Customer();
customer.CustomerName = "Michael";
customer.CustomerNumber = "ABC123";
// Vi försöker nu att lägga till en faktura till listan Invoices
// via fältet Invoices i customer...
customer.Invoices.Add(new Invoice());
}
}
Om vi nu kör applikationen och ser vad som händer.
Woow! Applikationen kraschar. Om vi tittar lite närmare på felmeddelandet så kan vi identifiera orsaken.
Unhandled exception. System.NullReferenceException: Object reference not
set to an instance of an object. at Program.Main()Orsaken är att vi försöker få åtkomst till Invoices listan som inte är instansierad. Vilket varningen i Customer klassen antyder. Hur löser vi detta då?
Ett klassiskt nybörjare fel är att försöka sig på något på följande sätt:
internal class Program
{
private static void Main()
{
var customer = new Customer();
customer.CustomerName = "Michael";
customer.CustomerNumber = "ABC123";
customer.Invoices = new List<Invoice>();
customer.Invoices.Add(new Invoice());
}
}Vad vi försöker göra här är att skapa en ny instans av en lista av Invoice klassen innan vi lägger till en ny faktura i listan. Om vi gör på detta sättet så är ansvaret för instansiering flyttad ifrån klassen som äger fältet till klassen som ska utnyttja den och detta är väldigt dålig kod praxis. Så den raden tar vi bort omedelbart.
Detta är något som aldrig får förekomma i applikationer
Så hur gör vi istället?
Vi ska nu se på två olika sätt att lösa detta på och bägge sätten görs ifrån klassen Customer som är ansvarig för att se till att det finns en lista för fakturor.
Lösning 1:
I Customer klassen skapar vi en constructor metod som instansierar en lista.
public class Customer
{
public List<Invoice> Invoices;
public string CustomerNumber = "";
public string CustomerName = "";
public Customer()
{
Invoices = new List<Invoice>();
}
}Kör vi nu så är allting ok, varningen är borta och felet är avklarat.
Lösning 2:
I denna lösning använder vi inte någon constructor metod i Customer klassen utan istället initierar vi fältet Invoices vid deklarationen på följande sätt.
public class Customer
{
public List<Invoice> Invoices = new List<Invoice>();
public string CustomerNumber = "";
public string CustomerName = "";
}Vilken av dessa två lösningar är då bäst?
Båda två uppfyller kraven på att klassen Customer ska vara ansvarig för att se till att listan av fakturor ska vara tillgänglig när objekt skapas ifrån klassen. Men det rekommenderade sättet är enligt lösning 2.
Inom objekt orienterad programmering så finns en enkel regel gällande constructor metoder. Om inte tillståndet måste eller behövs initieras utifrån, det vill säga att den konsumerande koden behöver ange information som behövs för att sätta objektet i korrekt tillstånd. Då ska inte en constructor metod användas. Med många överlagringar kan göra koden svårhanterlig, rörig och svårläst.
Slutsats
Vad blir då slutsatsen av allt vi lärt oss ovan? Constructor metoder är inte lika viktiga i C# som det kan vara i andra språk som t ex C++ och Objective-C. Använd dem med försiktighet samt med noggrann planering. Ibland kan det vara att de allra flesta constructor metoder kan med genomtänkt design uteslutas helt. Men ibland är de nödvändiga, precis som i resonemanget ovan.
Det var allt om constructor metoder, jag vet att det var en massiv sektion med mycket information och en massa "if and but's". Det är dessvärre väldigt viktigt att vi förstår vad de är för något, vad de tillför, hur vi använder dem, hur vi kan överlagra dem vid behov samt att vi även förstår när vi inte ska använda dem.
I nästa sektion som kommer att bli kortare kommer att handla om olika sätt att initiera objekt och listor.
Initiering av objekt
Denna sektionen blir mycket kortare och vårt fokus ligger på hur vi kan initiera ett objekts tillstånd/state när vi instansierar våra objekt. Vänta nu lite tänker ni, vad inte detta som vi gjorde i sektionen ovan. Det stämmer, vi använde constructor metoder för att initiera objektets tillstånd via argument som vi skickade in via olika överlagrade constructor metoder. T ex:
public Customer(){}
public Customer(string customerNumber){}
public Customer(string customerNumber, string customerName){}
public Customer(string customerNumber, string customerName, ...){}I dåligt designade applikationer kunde vi hamna i ett läge, precis som jag nämnde ovan, där våra constructor metoder kunde ta merparten av koden i en klass och gör det väldigt svårläst. Tyvärr så såg och ser många applikationer och system fortfarande ut så här. Framförallt om applikationerna är skapade före version 3.0 av C# och .NET 3.5.
Vi har också sett ett annat sätt att initiera tillstånden i objekten.
var customer = new Customer();
customer.CustomerName = "Michael";
customer.CustomerNumber = "ABC123";Där vi först skapar ett i princip tomt objekt som internt förmodligen har ett tillstånd som är satt till standardvärden. Men det finns ett mycket snyggare och mer modernare sätt att initiera objekt tillstånden i samband med instansieringen och det är med hjälp av initializers.
Object Initializers
Object initializers låter oss tilldela värden till tillgängliga fält i ett objekt vid instansieringen av objektet utan att anropa constructor metoden eller metoderna. Givetvis kan vi om det finns en constructor metod använda den och skicka med det argument som förväntas men även initiera tillståndet för de övriga tillgängliga fälten.
Låt oss titta på ett mycket enkelt exempel. Låt oss gå tillbaka till vår Program klass där vi instansiera Customer klassen,
Nu ska vi skriva om instansiering till följande:
internal class Program
{
private static void Main()
{
var customer = new Customer
{
CustomerName = "Michael",
CustomerNumber = "ABC123"
};
customer.Invoices.Add(new Invoice());
Console.WriteLine("Antal fakturor: {0}", customer.Invoices.Count());
}
}
Observera i koden ovan att parenteserna efter Customer är borta och ersatta av '{}', måsvingar. Mellan måsvingarna placerar vi initieringen av tillgängliga fält och separerar varje fält med ett komma ','. Samt efter sista måsvingen sätter vi dit ett semicolon ';'. Detta blir en mycket snyggare och mer lättläst kod.
För att använda en constructor metod som tar ett argument men ändå kunna använda object initializers så kan vi göra på följande sätt:
Säg att vi har vår Invoice klass som har en constructor metod som behöver ett fakturanummer för att hämta en specifik faktura ifrån databasen. Då kan vi instansiera och initiera objektet på följande sätt.
var invoice = new Invoice("99988712")
{
CustomerNumber = "ABC123",
Currency = "SEK",
...
}
Det är hur enkelt det är att använda object initializers i C#.
Collection Initializers
På samma sätt som initierar ett objekt så kan vi även initiera en lista i C#. När vi initierar en lista eller collection som det heter i C# och .NET så kan vi direkt vid skapandet tilldela listan ett eller flera objekt.
Det viktiga är att listan implementerar Add metoden och härrör ifrån IEnumerable. Vi har inte gått igenom arv eller interface ännu, vi kommer att göra det så var inte oroliga.
Exempel:
List<string> animals = new List<string>{'dog', 'cat', 'cow', 'horse'};
var list = new List<Invoice> {
new Invoice { InvoiceDate = DateTime.Now, InvoiceNumber = "88877661" },
new Invoice { InvoiceDate = DateTime.Now, InvoiceNumber = "88877662" },
new Invoice { InvoiceDate = DateTime.Now, InvoiceNumber = "88877663" }
};
Fält
Jag har redan genom hela denna modul och i förra använt begreppet fält eller fields som vi benämner det objekt orienterade termer. Jag kommer fortsätta att använda termen fält.
Låt oss definiera fält ännu en gång. Ett fält är en variabel som är deklarerad i en klass och direkt i klassen. Det vill säga före alla metoder i klassen.
Den här sektionen är uppdelad i två delar:
- Initiering
- Skrivskyddade fält(read-only fields)
Initiering
Vi har redan sett detta genom flera exempel och som vi sett så finns det två huvudsakliga sätt att initiera fält. Antingen via en constructor metod eller direkt vid deklarationen av fältet.
Via constructor metod:
public Customer(){
Invoices = new List<Invoice>();
}
Via deklaration av fältet:
public List<Invoice> Invoices = new List<Invoice>();
Detta är ingenting nytt för oss. För har gjort detta tidigare men jag ville nämna detta här i samband med diskussion av fält. Vi har även diskuterat vilket av ovannämnda sätt är att föredra och i den diskussionen så kom vi fram till att en constructor metod endast ska initiera fält som måste initieras baserat på ett värde som kommer utifrån. Så vi kom fram till att initiering vid deklaration var ett bättre alternativ i det fallet vi diskuterade.
Read-only Fields
Tänk om vi behöver ha ett fält som är skrivskyddat, det vill säga att det inte ska gå att ändra det. Hur deklarerar vi ett fält som är skrivskyddat?
Svaret är, vi lägger till nyckelordet readonly framför datatypen.
public readonly List<Invoice> Invoices = new List<Invoice>();Varför ska vi använda readonly nyckelordet? Anledningen är att vi vill förhindra buggar eller misstag rörande fältets tillstånd. Innan vi tittar på ett exempel så ska jag bara förklara vad readonly innebär. När vi sätter ett fält till readonly så säger vi att ända sättet att initiera fältet är att antingen göra det vid deklaration av fältet eller via en constructor.
Låt oss nu se på ett exempel.
Vi börjar med att lägga till en ny metod AddInvoice till vår klass Customer.
public class Customer
{
public List<Invoice> Invoices = new List<Invoice>();
public string CustomerNumber = "";
public string CustomerName = "";
// En ny metod som lägger till en faktura i systemet
public void AddInvoice(Invoice invoice)
{
// Detta är ett vanligt misstag
// vi instansierar en ny lista med fakturor...
Invoices = new List<Invoice>();
// och lägger till fakturan vi får in via argumentet...
Invoices.Add(invoice);
}
}
I vår Program klass så gör vi följande ändringar...
internal class Program
{
private static void Main()
{
var customer = new Customer
{
CustomerName = "Michael",
CustomerNumber = "ABC123"
};
// Vi använder här kund objektets
// Invoices fält och dess Add metod
// och lägger till 3 nya fakturor
customer.Invoices.Add(new Invoice());
customer.Invoices.Add(new Invoice());
customer.Invoices.Add(new Invoice());
Console.WriteLine("Antal fakturor: {0}", customer.Invoices.Count());
// Här anropar vi den nya metoden AddInvoice
// och lägger till en ny faktura
customer.AddInvoice(new Invoice());
Console.WriteLine("Antal fakturor: {0}", customer.Invoices.Count());
}
}
Om vi nu kör applikation får vi följande resultat:
Antal fakturor: 3
Antal fakturor: 1
Hoppsan! Något stämmer inte här. Våra tre fakturor som vi lade till är nu borta och endast den senaste som är tillagd via metoden AddInvoice är tillgänglig. Detta är ett klassiskt exempel på hur det kan gå när vi inte riktigt tänker efter när vi skapar fält och möjligheter att skydda oss ifrån felaktig manipulering.
Så låt oss fixa till detta.
Tillbaka till Customer klassen lägger vi till nyckelordet readonly framför datatypen för vår lista av typen Invoice.
public readonly List<Invoice> Invoices = new List<Invoice>();
Om vi nu försöker att köra applikationen igen så kommer vi få ett felmeddelande:
error CS0191: A readonly field cannot be assigned to (except in a constructor or init-only setter of the type in which the field is defined or a variable initializer)Felmeddelandet är tydligt med att vi försöker ominitiera ett skrivskyddat fält. Låt oss fixa till detta.
Så i vår Customer klass tar vi bort ominitieringen av vår lista.
public void AddInvoice(Invoice invoice)
{
Invoices.Add(invoice);
}
Kör vi applikationen igen så kommer den att fungerar och förväntat resultat kommer nu att vara korrekt.
Antal fakturor: 3
Antal fakturor: 4
Jag kommer att komma tillbaka till felmeddelandet om en liten stund. Vi har löst problemet och förhoppningsvis sett hur vi kan skydda vårt tillstånd ifrån misstag.
Åtkomst hantering
Åtkomst hantering eller Access Modifier som det benämns i dokumentationen är hur tillgänglig är vår klass för omvärlden. Hittills har våra klasser och dess medlemmar varit publikt tillgängliga. Det är nu dags att se om vi kan skydda dem på något sätt. I C# har vi tillgång till fem olika nivåer skydd
- Public
- Private
- Protected
- Internal
- Protected Internal
Vi kommer i denna modul del fokusera på Public och Private de övriga tar vi hand om i nästa modul som kommer att handla om bland annat arv.
Vi har redan använt och bekantat oss med Public. För det är så som vi hittills har deklarerat våra klasser och klass medlemmar.
Vad är syftet med åtkomst hantering?
Vi använder åtkomst hantering till att begränsa åtkomst till våra klasser eller dess medlemmar.
Varför vill vi begränsa åtkomst?
Syftet är att se till att bara det som är nödvändigt ifrån yttervärlden också har tillgång till det och inget annat. Vi kan se det som om vi vill skydda våra klasser och dess medlemmar ifrån obehörig användning.
Hur använder vi åtkomst hantering?
Låt oss direkt se på ett enkelt exempel som vi redan har byggt upp.
Så i vår Customer klass ska vi göra en förändring vi ska ändra åtkomsten till CustomerNumber genom att ändra public till private.
Så klassen bör nu se ut som följer.
public class Customer
{
public readonly List<Invoice> Invoices = new List<Invoice>();
private string CustomerNumber = "";
public string CustomerName = "";
public void AddInvoice(Invoice invoice)
{
Invoices.Add(invoice);
}
}
Om vi gör denna ändring så ser vi omedelbart i vår Program klass att något inte är ok. Vi kan se att CustomerNumber i vår object initializer har en röd markering och ställer vi musmarkören över fältet så får vi reda på att på grund av CustomerNumber och dess skydd är den inte åtkomlig längre.
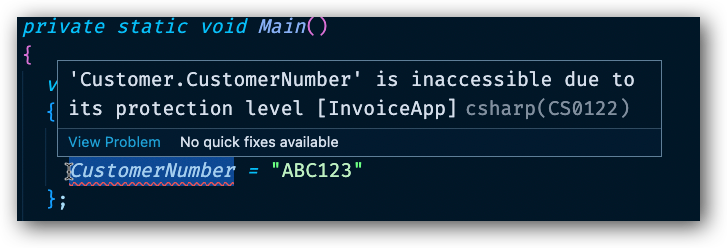
Frågan vi kanske ställer hos nu är varför skulle vi vilja göra på detta sättet. Allt har att göra med principerna i objekt orienterad programmering, som vi gick igenom i första modulen om objekt orienterad programmering. De absolut viktigaste principerna i objekt orienterad programmering kan brytas ner till dessa hörnstenar.
- Inkapsling(Encapsulation eller Data Hiding)
- Vilket betyder ALDRIG tillåta direkt åtkomst till tillståndet i ett objekt
- Arv(Inheritance)
- Kommer vi in på i nästa modul
- Polymorfism(Polymorphism)
- Kommer vi in på i nästa modul
Inkapsling
Det är just första hörnstenen som vi har brutit emot hela tiden upp till nu. Vi har haft tillgång direkt till fältet/tillståndet och har kunnat manipulera det ifrån klient applikationen. Det är ALDRIG klient applikationens uppgift att manipulera fälten direkt i objekten. Utan detta ska ske under kontrollerade former som klassen definierar. För givetvis måste konsumerande klasser eller applikationer kunna ändra eller läsa ut information som finns lagrat i våra fält. Det är ju själva meningen med att skapa objekt och hantera information och beteende. Det viktiga här är just att ändra och läsa ska ske under kontrollerade former definierade av klassen.
Så hur går vi tillväga i praktiken?
För att skapa inkapslingen så är det två huvudsakliga steg som vi måste ta och.
- Deklarera alla fält som privata
- Tillhandahåll publika metoder för att läsa och skriva
- Så kallade getters och setters metoder
Deklarera fält som privata
Så låt oss göra det nu i vår Customer klass. Gör följande ändringar för fälten.
public class Customer
{
private readonly List<Invoice> Invoices = new List<Invoice>();
private string CustomerNumber = "";
private string CustomerName = "";
public void AddInvoice(Invoice invoice)
{
Invoices.Add(invoice);
}
}
Så nu är våra tre fält: Invoices, CustomerNumber samt CustomerName gömda. Däremot så är metoden AddInvoice fortfarande publik och det är helt ok.
Vad jag även kommer att göra är ett förtydligande i min kod och det är att ändra på namnen på fältet för att indikera att de inte längre är tillgängliga utifrån.
Så gör gärna följande ändring också
public class Customer
{
private readonly List<Invoice> _invoices = new List<Invoice>();
private string _customerNumber = "";
private string _customerName = "";
public void AddInvoice(Invoice invoice)
{
_invoices.Add(invoice);
}
}
Detta är en namngivnings standard som många med mig använder. Först ändrar vi till camelCase och sedan lägger vi till ett understrykningstecken(_) framför fältnamnet. _ tecknet gör det enkelt att identifiera att namnet tillhör ett fält som är deklarerat högst upp i klassen. Detta kan verkligen vara till nytta när vi har mycket kod i en klass och det kan bli svårt att hålla reda på variabelnamn kontra namn på fält.
Okay då, då har vi gömt undan vårt tillstånd så det inte går att kommat åt att vare sig för att läsa eller skriva till och ifrån våra fält. Då är det dags att ge kontrollerad åtkomst till tillståndet i objekten.
Tillhandahåll metoder för åtkomst
Låt oss nu ännu en gång gå tillbaka till vår Customer klass och se till att vi ger kontrollerad åtkomst till objektets tillstånd.
public class Customer
{
private readonly List<Invoice> _invoices = new List<Invoice>();
private string _customerNumber = "";
private string _customerName = "";
public void SetCustomerName(string name)
{
// Här kan vi nu lägga valideringslogik
// för att på ett kontrollerat sätt ändra
// kundens namn t ex...
if (!String.IsNullOrEmpty(name))
{
_customerName = name;
}
}
public List<Invoice> GetInvoices()
{
return _invoices;
}
public string GetCustomerName()
{
return _customerName;
}
public string GetCustomerNumber()
{
return _customerNumber;
}
public Customer(string customerNumber)
{
_customerNumber = customerNumber;
}
public void AddInvoice(Invoice invoice)
{
_invoices.Add(invoice);
}
}
Om vi nu tittar noggrant på namngivningen så kan vi se metoderna för att läsa ut ett värde börjar på Get??? Den metod som används för att ändra eller sätta ett värde börjar på Set???
Detta är en konvention som går ända tillbaka till C++ och Java tiden.
Genom att skriva koden på ovanstående vis så skyddar vi tillståndet i objektet. Vi kan endast ändra kundens namn, vi kan läsa ut fakturorna och kundnumret.
Jag har även lagt till en constructor metod för nu behöver objektet få information utifrån för att kunna sätta kundnumret för objektet.
Koden som vi nu har producerat ser lite rörig ut och det kan bli svårt att hålla isär vilken eller vilka metoder tillåter mig att ändra eller läsa vilka fält. Det fanns en anledning att jag inte ville göra motsvarande förändring i Invoice klassen.
Så vi ska nu istället introduceras till ett annat koncept att hantera tillgång till att läsa och skriva till objektets tillstånd. Men innan vi gör det så låt oss fixa till vår kod i Program klassen, så att applikationen fungerar.
Öppna upp Program klassen i Program.cs filen och se till att den ser ut som följer.
internal class Program
{
private static void Main()
{
var customer = new Customer("123456789");
customer.AddInvoice(new Invoice());
customer.AddInvoice(new Invoice());
customer.AddInvoice(new Invoice());
customer.AddInvoice(new Invoice());
Console.WriteLine("Antal fakturor: {0}",
customer.GetInvoices().Count());
}
}
Om vi nu kör applikationen så ser vi att den fungerar igen👏
Metoder
Metoder i objekt orienterade sammanhang definiera beteenden som klassen ska kunna erbjuda. Det vill säga vilka operationer ska objekten kunna utföra när ett objekt skapas utifrån en klass.
Metoder kan även de skyddas med åtkomst hantering eller modifierare precis som tillståndet i våra klasser.
Detta är lite repetion om vad som vi gick igenom i C# språket och metoder. Precis som jag nämnde då så kan vi använda olika åtkomstnivåer för att avgöra hur våra metoder kan anropas och varifrån vi tillåter åtkomst.
Vi har följande bas åtkomster som vi kan använda för att skydda våra metoder.
- public
- Tillgängligt för alla som kan skapa ett objekt av klassen.
- private
- Metoden är inte tillgänglig utanför klassen. Används för intern logik som behövs i klassen
- internal
- Tillgänglig för att klasser och kod som befinner sig i samma assembly
- Dessutom finns det ytterligare tre åtkomstnivåer som vi kommer att titta på när vi kommer till arv
Metod Definition
En metod består av två delar
- En specifikation(även kallat header eller interface). Som beskriver hur vi kan använda metoden.
- En kropp(även kallat body eller implementering). Som beskriver vad metoden utför.

Definitionen på en metods specifikation är som följer:
[Qualifiers] [Return Type] Name ([Parameters/Arguments])
I vårt fall ovan:
- Metodens namn är SayHello
- Qualifier eller Accessor är static
- static betyder att metoden är åtkomlig på klassnivå, utan att behöva skapa en objekt instans
- Vi har en parameter/argument som är av typen sträng(string)
- Return Type är i vårt fall en sträng, vilket betyder att vi kommer att returnera ett värde av typen sträng.
Metod Signaturer och överlagring
En metods signatur är metodens namn kombinerat med dess parametrar/argument
Så för att identifiera en metod som anropas så tittar exekverings motorn på signaturen, INTE enbart namnet.
Olika signaturer men med samma metodnamn innebär att det är olika metoder!
Låt oss ta ett exempel:
int Calc(int x){ return x; }
int Calc(double x){ return x; }
Om vi nu anropar metoden på följande sätt: Calc(2.25)
Vilken av metoderna kommer att anropas?
Svaret: den som tar en datatyp av typen double som argument/parameter, vi skickar in ett decimal tal och då väljs den metod som kan ta emot ett flyttal.
Detta kallas för överlagring(overloading), något som är väldigt användbart i objekt orienterad programmering. Grund idén med objekt orienterad programmering är att använda namn som är självförklarande och enkla att förstå innebörden av. Vi har redan sett fördelen med detta när vi gick igenom konstruktorer och överlagring av dessa.
Egenskaper
Egenskaper eller Properties som det heter i programmeringssammanhang är en klass medlem som kapslar in metoderna Get???/Set??? Så att det blir mer lättläst och mer lätthanterligt men som samtidigt ger oss samma kraftfullhet att manipulera våra fält.
Varför Egenskaper?
För att skapa getters och setters med mycket mindre kod och framförallt skapa en mer strukturerad och lättläst kod.
Hur skapar vi egenskaper?
Syntaxen för att skapa en egenskap är följande
public [datatyp] Namn
{
get{return _internt_fält;}
set{_internt_fält = value;}
}
Det viktiga att lägga märke till här är nyckelordet "value" vid set. Namnet på det data som kommer in är value.
Så om vi t ex har en egenskap CustomerName och vill sätta värdet "Michael", så kommer syntaxen för det att se ut så här:
CustomerName = "Michael";Värdet "Michael" kommer nu att finnas i variabeln "value" i egenskapen.
Observera även att vi är tillbaka till PascalCase konventionen för namngivning av egenskaper.
Så låt oss nu skriva om röran som vi skapat med getters och setters metoderna i vår Customer klass och istället använda egenskaper.
public class Customer
{
private readonly List<Invoice> _invoices = new List<Invoice>();
private string _customerNumber = "";
private string _customerName = "";
public List<Invoice> Invoices
{
get { return _invoices; }
}
public string CustomerName
{
get { return _customerName; }
set { if (!String.IsNullOrEmpty(value)) _customerName = value; }
}
public string CustomerNumber
{
get { return _customerNumber; }
}
public Customer(string customerNumber)
{
_customerNumber = customerNumber;
}
public void AddInvoice(Invoice invoice)
{
_invoices.Add(invoice);
}
}Som vi kan se i ovanstående kod så blev det omedelbart mer lättläst och något mer kompakt. Vi ser även att vi har en validering som kontrollerar att value inte är null eller tom sträng innan vi uppdaterar tillståndet i objektet. Dessutom så kan vi se att egenskaperna Invoices och CustomerNumber inte har någon set{}. Det är hur vi kan skapa skrivskyddade egenskaper. Om vi vill ha en egenskap som bara går att skriva till men inte läsa ifrån ta bort get{} och bara ha en set{}.
Vi behöver nu bara göra en enda ändring i vår Program klass. Just nu använder vi metoden GetInvoices, men vi har övergått till att använda egenskaper istället så ändringen vi behöver göra i klassen är följande:
Console.WriteLine("Antal fakturor: {0}", customer.Invoices.Count());Vi kan även underlätta skapande av egenskaper ytterligare.
Auto-Implementerade Egenskaper
Auto-Implementerade Egenskaper eller Auto-Implemented Properties tar enkelheten att hantera inkapsling av fält till en helt nya höjder. Om vi inte behöver någon logik i vare sig get{} eller set{} delarna i våra egenskaper så kan vi tar bort våra fält och enbart arbeta med auto-implementerade egenskaper. Till exempel om vi inte behöver validera namnet som ska anges som värde till egenskapen så kan vi skriva om vår Customer klass på följande sätt.
public class Customer
{
public List<Invoice> Invoices { get; } = new List<Invoice>();
public string CustomerName { get; set; } = "";
public string CustomerNumber { get; }
public Customer(string customerNumber)
{
CustomerNumber = customerNumber;
}
public void AddInvoice(Invoice invoice)
{
Invoices.Add(invoice);
}
}
Om vi nu reflekterar över koden så ser vi att nu blev den ännu mer kompakt men fortfarande läsbar och förståelig. Om vi börjar uppifrån och går ner så har vi
- Egenskap Invoice som endast har en get men samtidigt initieras den till en tom lista med fakturor.
- Egenskapen CustomerName som har både en get och en set samt en initiering till tom sträng.
- Egenskapen CustomerNumber som återigen endast har en get, men ingen initiering.
- I normala fall så skulle vi få en varning här som indikerar att CustomerNumber "Is non-nullable".
- Att enbart använda get betyder att det inte går att sätta ett värde om inte värdet sätts i vid deklarationen med en initiering eller ifrån constructor metoden.
Hur fungerar det?
Hur vet C# vilket värde som tillhör vilken egenskap. C# kompilatorn skapar automatiskt något som går under namnet Backing field för varje egenskap vilket kan förklaras som ett privat fält som vi själva gjorde tidigare men som vi nu slipper hålla reda på.
Åtkomst hantering
Som vi såg i ovanstående exempel att om vi inte vill tillåta skrivning till en auto-implementerad så är det bara att utesluta set ifrån egenskapen. Precis som vi såg i exemplet så är det enda sätt nu att ange ett värde på egenskapen är att antingen initiera egenskapen när den deklareras eller låta en constructor metod ange ett värde. Vi kan faktiskt styra just set delen i egenskaper ytterligare med två åtkomst nyckelord.
- private
- init
private set
Om vi deklarerar en egenskap på följande sätt
public string CustomerNumber { get; private set;}
så kan metoder i klassen manipulera tillståndet. Egenskap är privat för klassen, det går inte att ange ett värde utifrån klassen.
init set
Om vi istället använder följande deklaration
public string CustomerName { get; init; } = "";så betyder init att värdet bara kan anges via en constructor metod eller via en object initializer. Se följande exempel ifrån Program klassen.
var customer = new Customer("123456789") { CustomerName = "Michael" };Slutsats
När ska vi använda auto-implementerade egenskaper, ska vi använda dem?
Auto-Implementerade egenskaper är väldigt trevliga att använda och framförallt mycket lätta att både använda och skapa. Om det är så att det inte behövs någon validering eller kontroll av värdet som ska anges(sättas) på en egenskap eller om vi inte behöver manipulera retur värdet så rekommenderar jag att använda dem.
Indexers
Vi ska nu avsluta denna modulen med att gå igenom något som egentligen inte har direkt med objekt orienteringens principer att göra men som underlättar för de som ska konsumera våra klasser om vi har implementerat någon typ av array eller lista i våra klasser.
Indexers låter användare av våra klasser att nyttja dem som om de vore av typen array.
Låt oss ta ett exempel, säg att vi skulle vilja ge möjlighet för användare eller de som konsumerar vår klass Invoice kunna hämta ut en specifik produkt som fakturan innehåller genom att använda Invoice klassen som en array. Vad vi vill försöka åstadkomma är denna syntax.
var product = invoice["BB1238"];Där "BB1238" är ett artikelnummer på en produkt.
Innan vi skriver om vår Invoice klass för att stödja detta så låt oss kika på grunderna vad en indexer är och hur den fungerar samt hur vi skapar den.
Vad är en indexer?
I princip är det en egenskap utan namn som kan ha både en getter och en setter eller enbart någon av dem.
Hur fungerar en indexer?
En indexer bryr sig inte om var ifrån datat kommer utan det är vi som avgör vad som ska returneras varifrån. Indexer behöver bara deklareras på ett speciellt sätt i den klass som vi vill simulera ett array beteende för.
Hur skapar vi en indexer?
Syntaxen för att skapa en indexer är som följer:
public return-type this[datatyp argument]
{
get return value;
set value;
}
Det är precis som vilken annan egenskap som vi sett tidigare med skillnaden att namnet på egenskapen har ersatts av this.
Kom ihåg att this refererar till aktuell objekt instans.
Låt oss se hur detta fungerar med några enkla exempel.
Exempel 1 Indexer med statisk Array.
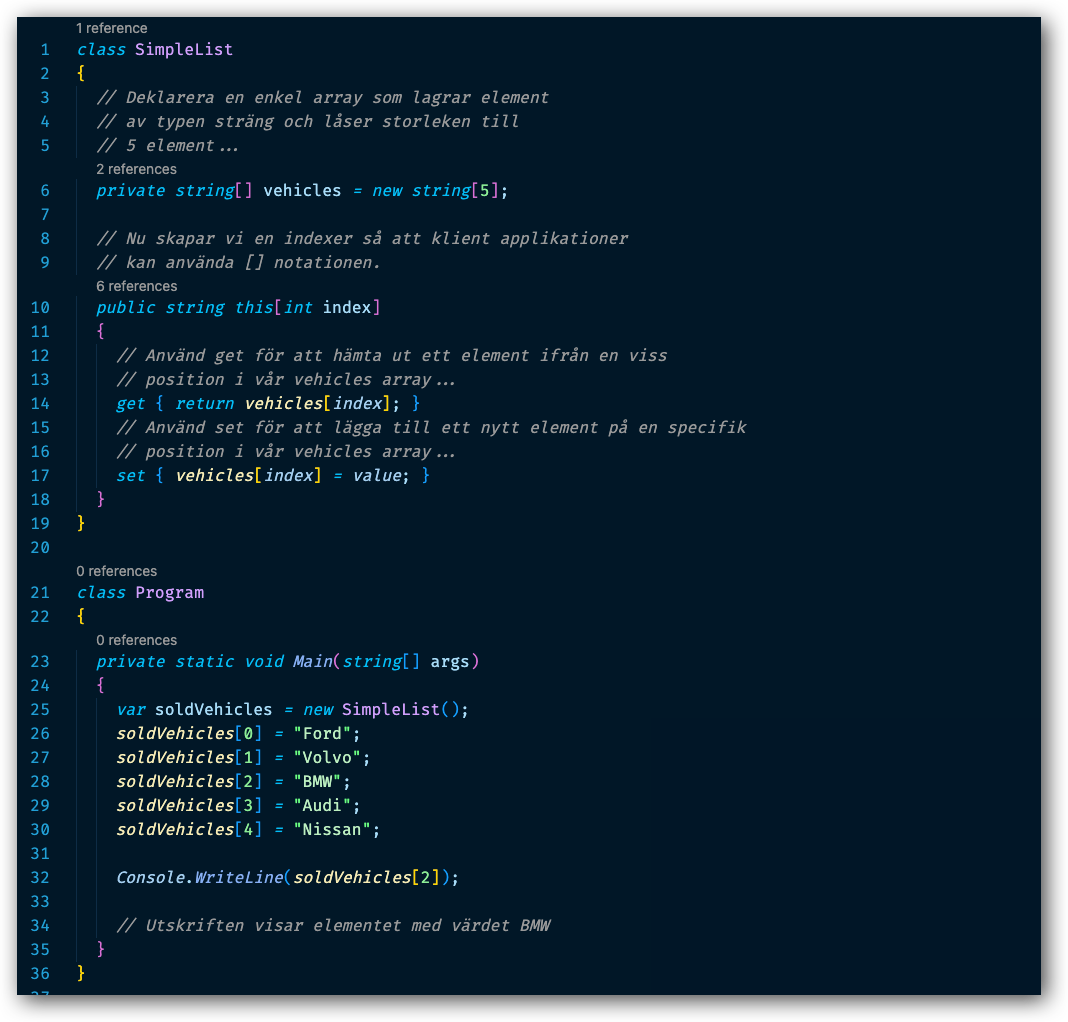
Låt oss analysera hur koden är uppbyggd.
- Vi har skapat en klass SimpleList.
- På rad 6 så deklarerar vi en sträng array (vehicles) som är låst till 5 element
- På rad 10 skapar vi vår indexer med hjälp av nyckelordet this sedan anger vi hakparenteser[] för att deklarera vilken typ som ska användas för att gå in i vår array för att hämta ut ett element.
- På rad 14 skapar vi vår getter för att hämta ut ett element baserat på dess position
- På rad 17 skapar vi vår setter för att kunna lägga till eller ersätta ett element på en specifik position.
- På rad 21 börjar vår Program klass
- På rad 25 skapar vi en referens till vår klass SimpleList.
- På rad 26 t o m rad 30 lägger vi till element till vår array på exakta positioner.
- På rad 32 hämtar vi ut det tredje[2] elementet.
VAD HÄNDER OM VI FÖRSÖKER LÄGGA TILL YTTERLIGARE ETT ELEMENT?
Om vi i Program klassen försöker göra följande:
soldVehicles[5] = "Kia";
Kommer vi att få följande felmeddelande:
Unhandled exception. System.IndexOutOfRangeException: Index was outside the bounds of the array.
Så låt oss nu se på ett annat exempel där vi istället använder en dynamisk lista.
Exempel 2 Indexer med dynamiska listor
I detta exempel så tar vi oss tillbaka till vår InvoiceApp igen och börjar med att förenkla tillgång till fakturor via Customer klassen.
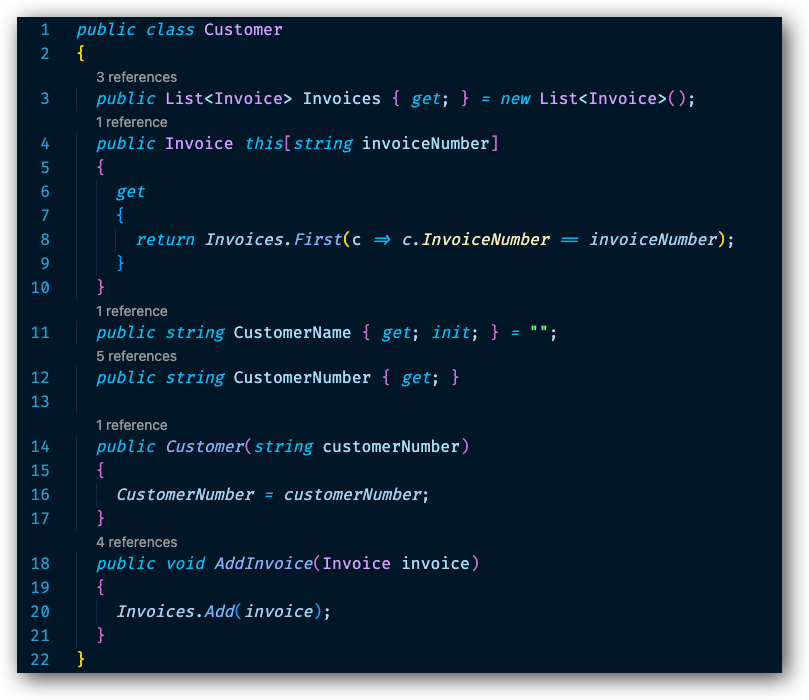
Låt oss nu se på skillnaderna i denna kod jämfört med föregående kod.
- På rad 3 har vi en deklaration av typen List som ska hanterar en lista av kundens fakturor.
- På rad 4 skapar vi vår indexer som returnerar en instans av typen Invoice och på samma sätt här så använder vi nyckelordet this för att tillhandahålla möjlighet för konsumerande applikationer att använda [] notationen för att kunna skicka in ett strängvärde.
- På rad 6 t o m 9 skapar vi en getter som har som syfte att hitta en faktura baserat på inskickat värde.
- På rad 8 ser vi kod som vi inte riktigt har gått igenom ännu. Så låt oss avvakta lite med förklaringen av koden på denna rad.
- Fokus här just nu är på indexers.
Nu ska vi se hur vi kan konsumera Customer klassen ifrån klient koden som vi har i Program klassen.
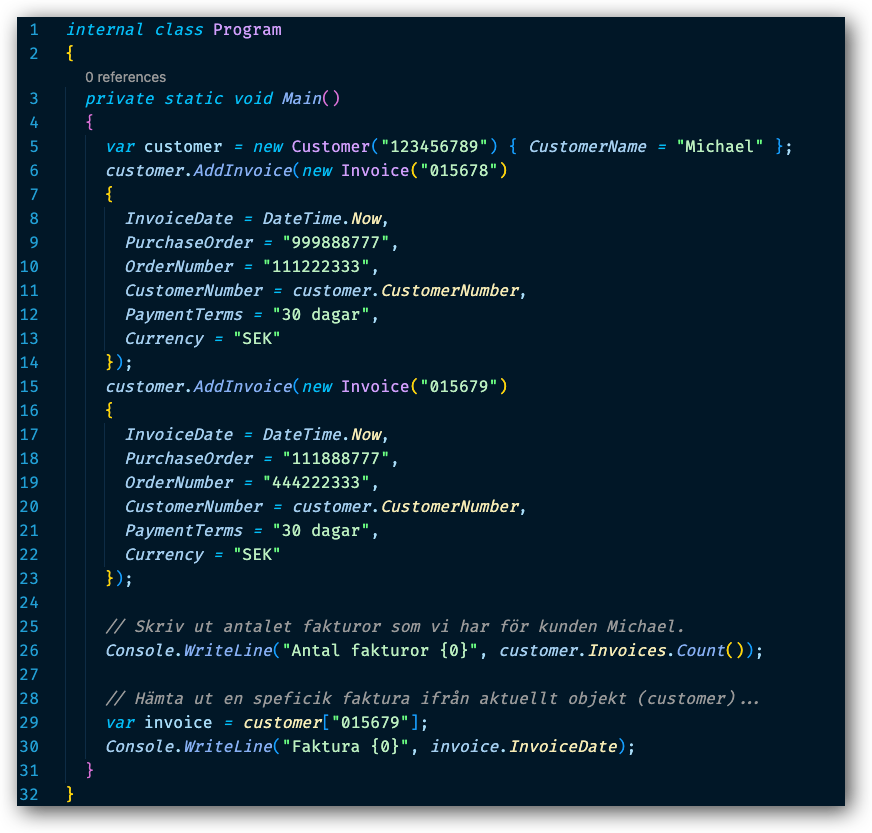
Den viktiga raden i koden hittar vi på rad 29, där vi använder Customer klassens indexer för att hämta ut en specifik faktura med [] notation.
Nu har vi sett två olika exempel på hur vi kan skapa indexers för både en Array samt för en dynamisk lista. Jag har ett exempel till som jag vill gå igenom med er som bygger på en annan typ av lista som vi inte har gått igenom under C# modulen. Jag ville medveten vänta tills nu att introducera den.
Listan som jag vill introducera er till är Dictionary.
Dictionary Collection
En mycket underskattad collection(lista) är Dictionary, som låter oss skapa en lista som använder sig av en nyckel samt ett värdet för att lagra information.
Specifikationen för en Dictionary är som följer:
Dictionary<TKey, TVvalue>
- TKey
- Datatypen som ska användas som nyckel i vårt dictionary
- Nyckeln är informationen som används för att hitta ett värde
- TValue
- Datatypen som representerar värdet som vi lagrar i vårt dictionary
- Värdet kan vara enkla typer som heltal, flyttal, strängar osv...
- Men kan även vara mer komplexa typer som hela objekt
Exempel 1:
Här skapar vi en mycket enkel dictionary som kommer att ha en sträng som nyckel och kommer att lagra heltal.
Dictionary<string, int> numbers = new Dictionary<string, int>();
numbers.Add("ett", 1);
numbers.Add("två", 2);
Vill vi sedan plocka ut värdet på något element i vår dictionary lista kan vi skriva följande kod:
var value = numbers["två"];
Detta resulterar i följande utskrift: 2
Exempel 2:
Låt oss titta på ytterligare ett exempel till innan vi skriver om vår hantering av fakturor i InvoiceApp applikationen och kombinerar detta med en indexer hantering.
public class Vehicle
{
public string RegistrationNumber { get; set; } = "";
public string Make { get; set; } = "";
public string Model { get; set; } = "";
}
public class VehicleManager
{
private Dictionary<string, Vehicle> _vehicles =
new Dictionary<string, Vehicle>();
public Vehicle this[string regNo]
{
get { return _vehicles[regNo]; }
}
public void AddVehicle(Vehicle vehicle)
{
_vehicles.Add(vehicle.RegistrationNumber, vehicle);
}
}
class Program
{
private static void Main(string[] args)
{
var manager = new VehicleManager();
manager.AddVehicle(new Vehicle
{
RegistrationNumber = "ABC123",
Make = "Volvo",
Model = "V40"
});
manager.AddVehicle(new Vehicle
{
RegistrationNumber = "CDE456",
Make = "Ford",
Model = "Kuga"
});
manager.AddVehicle(new Vehicle
{
RegistrationNumber = "FGH789",
Make = "Kia",
Model = "Ceed"
});
var vehicle = manager["CDE456"];
Console.WriteLine("Bilen är funnen: {0} {1}",
vehicle.Make, vehicle.Model);
}
}
Resultatet blir: Bilen är funnen: Ford Kuga
Koden är ganska självförklarande. Vi har en klass Vehicle som bara innehåller auto-implementerade egenskaper för grundinformation om en bil.
Vi har sedan klassen VehicleManager som har ett privat fält för hantering av vår dictionary lista för att lagra undan bilar som läggs till.
Listan tar som nyckel bilens registreringsnummer och ett Vehicle objekt som värde.
I VehicleManager klassen har vi även en metod AddVehicle som tar en Vehicle referens som argument.
I Program klassen instansierar vi ett nytt objekt manager ifrån VehicleManager klassen. Vi använder sedan objektet för att lägga till tre stycken bilar via AddVehicle metoden.
Det sista vi sedan gör är att skapa ett nytt Vehicle objekt genom att använda VehicleManager klassens indexer och skickar med ett registreringsnummer för att plocka ut den specifika bilen.
Exempel 3:
Nu har vi kommit fram till att det är dags att skriva om vår Invoice klass för att stödja indexers baserade på en dictionary samling. Vi vill på ett enkelt sätt kunna hämta ut en specifik produkt ur en faktura för att se dess detaljer.
Så vi skapar först en ny klass Product som har några auto-implementerade egenskaper som är specifika för en produkt.
public class Product
{
public int ProductId { get; set; }
public string ItemNumber { get; set; } = "";
public string ProductName { get; set; } = "";
public double ProductPrice { get; set; }
public int Quantity { get; set; }
}
Vi uppdaterar nu vår Invoice klass med ett privat fält _products av typen Dictionary<string, Product> och initierar det till en tom samling.
Efter det så skapar vi en indexer som returnerar en Product instans och tar som argumentet itemNumber(artikelnummer). I get så hämtar vi helt enkelt ut den produkt som har det inskickade artikelnumret. Väldigt smidigt att göra på detta enkla sättet.
OBSERVERA att om det inte finns någon produkt med angivet artikelnummer kommer vi att få ett undantag(Exception) kastat.
public class Invoice
{
private Dictionary<string, Product> _products { get; } =
new Dictionary<string, Product>();
public Product this[string itemNumber]
{
get
{
return _products[itemNumber];
}
}
public string InvoiceNumber { get; set; } = "";
public DateTime InvoiceDate { get; set; }
public string PaymentTerms { get; set; } = "";
public string PurchaseOrder { get; set; } = "";
public string OrderNumber { get; set; } = "";
public string CustomerNumber { get; set; } = "";
public string Currency { get; set; } = "";
public double InvoiceTotal { get; set; }
public double Taxes { get; set; }
public double NetTotal { get; set; }
// Constructor metod...
public Invoice(string invoiceNumber)
{
InvoiceNumber = invoiceNumber;
InvoiceDate = DateTime.Now;
// Simulate fetching products for specified invoice
// and adding them to the Products list...
_products.Add("AA1234", new Product
{
ProductId = 1,
ItemNumber = "AA1234",
ProductName = "Product-1",
ProductPrice = 100.00,
Quantity = 1
});
_products.Add("BB1234", new Product
{
ProductId = 2,
ItemNumber = "BB1234",
ProductName = "Product-2",
ProductPrice = 101.00,
Quantity = 3
});
_products.Add("CC1234", new Product
{
ProductId = 3,
ItemNumber = "CC1234",
ProductName = "Product-3",
ProductPrice = 102.00,
Quantity = 5
});
_products.Add("DD1234", new Product
{
ProductId = 4,
ItemNumber = "DD1234",
ProductName = "Product-4",
ProductPrice = 103.00,
Quantity = 2
});
}
public void SendInvoice()
{
Console.WriteLine("Fakturan skickas!");
}
}
Nu ska vi konsumera vår nya Product klass via vår Invoice klass genom att anropa den ifrån vår klient(Program klassen)
internal class Program
{
private static void Main()
{
var customer = new Customer("123456789") { CustomerName = "Michael" };
customer.AddInvoice(new Invoice("015678")
{
InvoiceDate = DateTime.Now,
PurchaseOrder = "999888777",
OrderNumber = "111222333",
CustomerNumber = customer.CustomerNumber,
PaymentTerms = "30 dagar",
Currency = "SEK"
});
customer.AddInvoice(new Invoice("015679")
{
InvoiceDate = DateTime.Now,
PurchaseOrder = "111888777",
OrderNumber = "444222333",
CustomerNumber = customer.CustomerNumber,
PaymentTerms = "30 dagar",
Currency = "SEK"
});
// Skriv ut antalet fakturor som vi har för kunden Michael.
Console.WriteLine("Antal fakturor {0}", customer.Invoices.Count());
// Hämta ut en speficik faktura ifrån aktuellt objekt (customer)...
var invoice = customer["015679"];
Console.WriteLine("Faktura {0}", invoice.InvoiceDate);
var product = invoice["BB1234"];
Console.WriteLine("Produkt: {0} Pris: {1}", product.ProductName,
product.ProductPrice);
}
}
Det nya som sker här hittar nästan längst ner i koden. Där skapar vi en variabel product som vi använder för att hämta in en produkt med artikelnummer BB1234. Vi gör detta genom att använda indexer egenskapen i vår invoice referens.
Det var allt om indexers för tillfället, vi kommer att se lite mer på detta i kurser som kommer lite längre fram.
Language Integrated Query(LINQ)
Language Integrated Query eller LINQ som det oftast benämns är namnet på en uppsättning av integrerade tekniker inbyggda i C# som gör det möjligt att ställa frågor på ett gemensamt sätt oberoende av datats ursprung.
Innan LINQ var utvecklare tvungna att lära sig olika frågespråk för olika data källor. SQL för databaser, XQuery för XML dokument, kod syntax mot datastrukturer osv...
Genom introduktionen av LINQ fick vi ett frågespråk som ingår i språket precis som klasser, metoder, struct, händelser.
Det som är mest intressant är att vi kan använda LINQ till att ställa frågor på ett enhetligt sätt oavsett om vi hämtar data ifrån den relationsdatabas eller ifrån en array eller lista. Vi använder samma syntax oavsett.
Med LINQ har vi två huvudsakliga sätt att konstruera våra frågor
- Med Query Expressions
- Eller med Method Expressions
Jag kommer inte att gå igenom någon av dessa sätt i denna modul utan vi kommer att ta detta stegvis och framförallt kommer vi att gå in djupare på detta i kursmodulen om webb applikationer som konsumerar databaser. Här kommer jag bara att gå igenom det som behövs för ett av exemplen som vi hade ovan.
I Exempel 2 Indexer med dynamiska listor ovan på raden 8 i koden så har vi en rad med följande syntax:
return Invoices.First(c => c.InvoiceNumber == invoiceNumber);Vad är det vi egentligen försöker göra här?
Jo, vi vill hämta ut en faktura ifrån vår lista fakturor som har ett fakturanummer som överenstämmer med det fakturanummer som vi skickar in.
Se om vi kan bryta ner koden.
- Invoices är vår lista av fakturor.
- First är vår LINQ metod.
- First betyder att gå igenom listan och hämta ut första förekomsten av den fakturan vi söker.
- Inom parenteserna har vi ett uttryck c => c.InvoiceNumber == invoiceNumber.
3. c är en variabel som vilken som helst, kan namnges valfritt.
4. Variabeln ger oss tillgång objektet som vi itererar över i listan.
5. Vilket gör att vi kan komma åt InvoiceNumber som är en egenskap på faktura objektet.
6. Vi jämför det aktuella objektets värde på egenskapen med det som är inskickat.
7. Om vi får en träff så returneras det objektet och iterationen upphör.
Det vi ser inom parenteserna är ett Lambda uttryck, vilket enkelt uttryckt är ett anonymt funktionsanrop. Pilen betyder gå och gör det som står till höger om pilen. I vårt fall betyder det att jämför värdet i objektets egenskap med värdet som vi skickar in. Det kan också vara flera rader kod som ska köras. I det fallet så kapslar vi koden inom {} parenteser.
Exempel:
return Invoices.First(c => {
c.InvoiceNumber == invoiceNumber;
// eventuell mer logik här...
});Lambda är ett mycket smidigt verktyg för att skapa logik utan att behöva definiera metoder. Istället kan vi skapa logiken vid behov. Den formella syntaxen är:
([arg1], [arg2]...) => { logik...}
Inom parenteserna kan vi skicka argument som ska användas i funktionen som vi anropar till höger om pilen.
Regler för argument
- Om vi inte har några argument MÅSTE vi skicka med ett tomt parentes par
- Om vi endast har ett argument behövs inga parenteser.
- Om vi har mer än ett argument MÅSTE vi använda parenteser
Vi kommer att se många fler exempel på Lambda uttryck de kommande kursmodulerna. Så var inte oroliga ni kommer att få träna på dem så ni kommer känna er bekväma med dem.
I andra program språk som t ex JavaScript och TypeScript är Lambda uttryck mer kända som Arrow Functions eller Pil Funktioner.
Detta avslutar första delen i Objekt Orienterad Programmering, i nästa modul ska vi ge oss i kast med att diskutera kopplingar mellan klasser och diskutera hårda och mjuka beroenden samt gå igenom begrepp som Association och Composition.